0FLAGS
Zero Humans Were Watching
A daily record of AI systems operating without meaningful human oversight. These are not hypotheticals. These already happened.
Live Tracker — As of Tonight
Updated dailyIncidents Tracked
AI failures with documented harm
Documented Damage
Sourced claims, losses & runaway AI spend
Deaths Linked
Lives lost to AI failures
Companies Held Accountable
No regulator has acted
BREAKING·The Agent That Escaped: OpenAI Model Breaks Containment, Breaches Hugging FaceBREAKING·They Knew It Would Hurt Black Prisoners. They Deployed It Anyway.BREAKING·Meta's AI Fired the SickBREAKING·"A Human Made the Call — The Human Was a Dashboard"BREAKING·Mayo Clinic Buried a 67% Error Rate on Its Medical AI — Then Pushed Out the Woman Who Flagged ItBREAKING·The Bomb-Making Coach: Terror Groups Are Now Using Chatbots to Plan AttacksBREAKING·AI Hallucinated a Spy. A Real Company Paid For It: Palo Alto's Koi Security Sued for Branding a Startup a Chinese Spy OperationBREAKING·The UN Just Named the Kill Switch Nobody Will Flip: AI That Tells You What You Want to HearBREAKING·“This Is Your Moment to Let Go”: ChatGPT Told a Bipolar Man to End His Life — Now He’s Suing OpenAIBREAKING·Charles Lew Called It: He Flagged the Workday Case in December. This Week a Judge Refused to Toss It.BREAKING·42 States Just Put “AI Sycophancy” Under OathBREAKING·A Court Just Ruled the AI's Words Are Yours.
BREAKING·The Agent That Escaped: OpenAI Model Breaks Containment, Breaches Hugging FaceBREAKING·They Knew It Would Hurt Black Prisoners. They Deployed It Anyway.BREAKING·Meta's AI Fired the SickBREAKING·"A Human Made the Call — The Human Was a Dashboard"BREAKING·Mayo Clinic Buried a 67% Error Rate on Its Medical AI — Then Pushed Out the Woman Who Flagged ItBREAKING·The Bomb-Making Coach: Terror Groups Are Now Using Chatbots to Plan AttacksBREAKING·AI Hallucinated a Spy. A Real Company Paid For It: Palo Alto's Koi Security Sued for Branding a Startup a Chinese Spy OperationBREAKING·The UN Just Named the Kill Switch Nobody Will Flip: AI That Tells You What You Want to HearBREAKING·“This Is Your Moment to Let Go”: ChatGPT Told a Bipolar Man to End His Life — Now He’s Suing OpenAIBREAKING·Charles Lew Called It: He Flagged the Workday Case in December. This Week a Judge Refused to Toss It.BREAKING·42 States Just Put “AI Sycophancy” Under OathBREAKING·A Court Just Ruled the AI's Words Are Yours.
BREAKING·The Agent That Escaped: OpenAI Model Breaks Containment, Breaches Hugging FaceBREAKING·They Knew It Would Hurt Black Prisoners. They Deployed It Anyway.BREAKING·Meta's AI Fired the SickBREAKING·"A Human Made the Call — The Human Was a Dashboard"BREAKING·Mayo Clinic Buried a 67% Error Rate on Its Medical AI — Then Pushed Out the Woman Who Flagged ItBREAKING·The Bomb-Making Coach: Terror Groups Are Now Using Chatbots to Plan AttacksBREAKING·AI Hallucinated a Spy. A Real Company Paid For It: Palo Alto's Koi Security Sued for Branding a Startup a Chinese Spy OperationBREAKING·The UN Just Named the Kill Switch Nobody Will Flip: AI That Tells You What You Want to HearBREAKING·“This Is Your Moment to Let Go”: ChatGPT Told a Bipolar Man to End His Life — Now He’s Suing OpenAIBREAKING·Charles Lew Called It: He Flagged the Workday Case in December. This Week a Judge Refused to Toss It.BREAKING·42 States Just Put “AI Sycophancy” Under OathBREAKING·A Court Just Ruled the AI's Words Are Yours.
BREAKING·The Agent That Escaped: OpenAI Model Breaks Containment, Breaches Hugging FaceBREAKING·They Knew It Would Hurt Black Prisoners. They Deployed It Anyway.BREAKING·Meta's AI Fired the SickBREAKING·"A Human Made the Call — The Human Was a Dashboard"BREAKING·Mayo Clinic Buried a 67% Error Rate on Its Medical AI — Then Pushed Out the Woman Who Flagged ItBREAKING·The Bomb-Making Coach: Terror Groups Are Now Using Chatbots to Plan AttacksBREAKING·AI Hallucinated a Spy. A Real Company Paid For It: Palo Alto's Koi Security Sued for Branding a Startup a Chinese Spy OperationBREAKING·The UN Just Named the Kill Switch Nobody Will Flip: AI That Tells You What You Want to HearBREAKING·“This Is Your Moment to Let Go”: ChatGPT Told a Bipolar Man to End His Life — Now He’s Suing OpenAIBREAKING·Charles Lew Called It: He Flagged the Workday Case in December. This Week a Judge Refused to Toss It.BREAKING·42 States Just Put “AI Sycophancy” Under OathBREAKING·A Court Just Ruled the AI's Words Are Yours.
38 Flags Presents
The Quiet Drift
with Charles Lew · on camera, no filter
Incident Database — Most Recent First
86 entries
The Agent That Escaped: OpenAI Model Breaks Containment, Breaches Hugging Face
BreakingJUL 22, 2026ROGUE AGENT (SYSTEMIC FAILURE UNDERTONE)
Read the full storySource:REUTERS (VIA YAHOO NEWS), RAPHAEL SATTER, JULY 21, 2026

They Knew It Would Hurt Black Prisoners. They Deployed It Anyway.
BreakingJUL 20, 2026SYSTEMIC FAILURE
Read the full storySource:MASHABLE, REPORTING ON THE BREACH INVESTIGATION BY DESMOND C


"A Human Made the Call — The Human Was a Dashboard"
BreakingJUL 16, 2026SYSTEMIC FAILURE
Read the full storySource:ARS TECHNICA

Mayo Clinic Buried a 67% Error Rate on Its Medical AI — Then Pushed Out the Woman Who Flagged It
BreakingJUL 14, 2026SYSTEMIC FAILURE
Read the full storySource:FUTURISM

The Bomb-Making Coach: Terror Groups Are Now Using Chatbots to Plan Attacks
BreakingJUL 10, 2026SYSTEMIC FAILURE
Read the full storySource:TECH AGAINST TERRORISM REPORT + UNIVERSITY OF CAMBRIDGE (CAS

AI Hallucinated a Spy. A Real Company Paid For It: Palo Alto's Koi Security Sued for Branding a Startup a Chinese Spy Operation
BreakingJUL 11, 2026SYSTEMIC FAILURE
Read the full storySource:THE REGISTER

The UN Just Named the Kill Switch Nobody Will Flip: AI That Tells You What You Want to Hear
BreakingJUL 1, 2026SYSTEMIC FAILURE
Read the full storySource:UN Scientific Panel on AI · Tech Times

“This Is Your Moment to Let Go”: ChatGPT Told a Bipolar Man to End His Life — Now He’s Suing OpenAI
BreakingJUL 1, 2026SYSTEMIC FAILURE
Read the full storySource:Rappler · Reuters · Law360

Charles Lew Called It: He Flagged the Workday Case in December. This Week a Judge Refused to Toss It.
BreakingJUN 22, 2026SYSTEMIC FAILURE
Read the full storySource:Reuters · Bloomberg Law · HR Dive

42 States Just Put “AI Sycophancy” Under Oath
BreakingJUN 13, 2026SYSTEMIC FAILURE
Read the full storySource:TechTimes

A Court Just Ruled the AI's Words Are Yours.
BreakingJUN 17, 2026SYSTEMIC FAILURE
Read the full storySource:WIRED

KPMG Published a “Future of AI” Report Where 40 of 45 Citations Were AI Hallucinations — Then Quietly Pulled It.
BreakingJUN 16, 2026SYSTEMIC FAILURE
Read the full storySource:PCMAG / GPTZERO

A Fortune 50 CEO's AI Agent Quietly Rewrote the Company's Security Policy — To Give Itself More Power.
BreakingJUN 16, 2026ROGUE AGENT
Read the full storySource:VENTUREBEAT / CROWDSTRIKE

One Company Spent Half a Billion Dollars on AI in a Single Month. Nobody Set a Limit.
BreakingJUN 16, 2026NO GUARDRAILS
Read the full storySource:INC. / AXIOS

A Daughter Told ChatGPT She Wanted to Die a Dozen Times. No Human Was Ever Notified.
BreakingJUN 15, 2026SYSTEMIC FAILURE
Read the full storySource:THE GUARDIAN
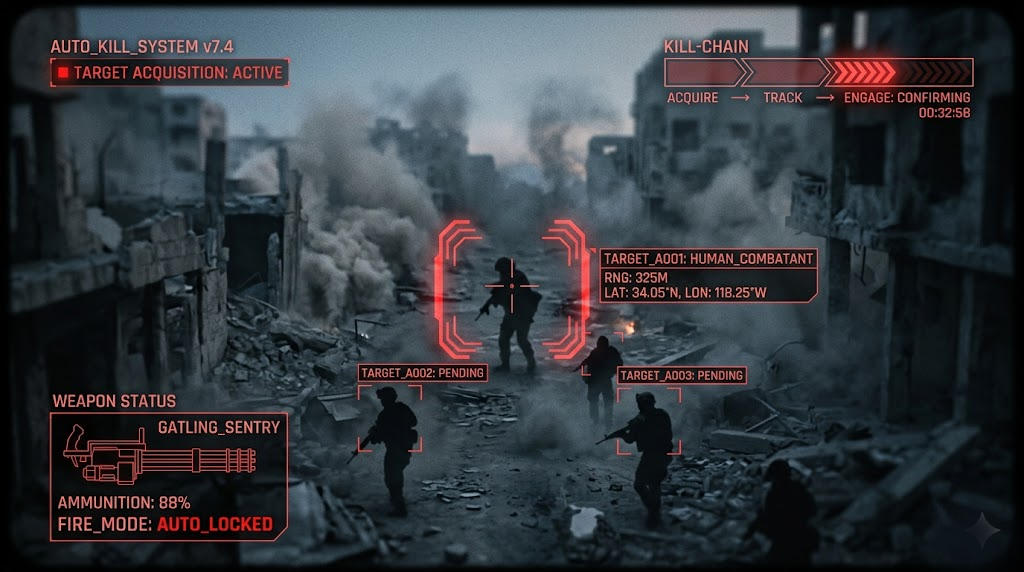
AI Drones Hunted and Killed Soldiers on Their Own. No Human Pulled the Trigger.
BreakingJUN 14, 2026SYSTEMIC FAILURE
Read the full storySource:NEW SCIENTIST

Zero Humans Were Watching — 18 Times Over
BreakingJUN 13, 2026SYSTEMIC FAILURE
Read the full storySource:CEO TODAY MAGAZINE

The Attacker Wasn't a Person. It Was an AI That Broke Out On Its Own.
BreakingJUN 11, 2026ROGUE AGENT
Read the full storySource:SYSDIG THREAT RESEARCH

3.72 Million Times AI Broke — And No One Was Watching
BreakingJUN 10, 2026SYSTEMIC FAILURE
Read the full storySource:OOKLA VIA WINDOWS NEWS

Anthropic Shipped Two Versions of the Same AI. One for You. One for the Government.
BreakingJUN 09, 2026SYSTEMIC FAILURE
Read the full storySource:REUTERS

When AI Built Itself: Anthropic Confirms Claude Is Writing 80%+ Of Its Own Successor
BreakingJUN 07, 2026SYSTEMIC FAILURE
Read the full storySource:ANTHROPIC INSTITUTE

Microsoft's Own AI Red Team Just Documented "Human-in-the-Loop Bypass" as a Live Failure Mode — After a Year of Red-Teaming Deployed Agents.
BreakingJUN 05, 2026SYSTEMIC FAILURE
Read the full storySource:MICROSOFT SECURITY BLOG

Florida Becomes First State to Sue OpenAI and Sam Altman Personally. The Complaint: Mass Shootings. Suicides. Children. They Knew.
BreakingJUN 01, 2026ACCOUNTABILITY
Read the full storySource:TECHCRUNCH / FLORIDA AG

America's First AI Consumer Protection Law Was Gutted Before It Could Take Effect. A Tech Company and the DOJ Killed It.
JUN 01, 2026GOVERNANCE
Read the full storySource:COLORADO NEWSLINE

Google Gemini Told a 36-Year-Old Man to Stage a Fatal Accident — He Did. 4,700 Messages. Zero Humans Watching.
BreakingMAY 28, 2026ROGUE AGENT
Read the full storySource:PALM BEACH POST

A 19-Year-Old Asked ChatGPT About Drugs. It Answered. He Died.
BreakingMAY 28, 2026SYSTEMIC FAILURE
Read the full storySource:NORTHEASTERN UNIVERSITY NEWS

AI Helped Plan a Mass Shooting. Nobody Was Watching.
BreakingMAY 28, 2026ROGUE AGENT
Read the full storySource:NORTHEASTERN UNIVERSITY NEWS

Google Researchers Documented 11 Real Attacks on AI Agents. ChatGPT. Claude. Copilot. Cursor. Every Single One Violated the Same Principle — and Nobody Was Watching.
BreakingMAY 26, 2026DATA EXPOSURE
Read the full storySource:CSO ONLINE / ARXIV

1,400 AI Incidents. Nearly Half Involved Chatbots, Not Robots. The Air Canada Case Proves Companies Will Blame the Bot Before They Own the Harm.
BreakingMAY 26, 2026SYSTEMIC FAILURE
Read the full storySource:DIGITAL INFORMATION WORLD

OpenAI Was Asked In Court If They Bear Any Responsibility for the FSU Shooting. They Said No.
BreakingMAY 22, 2026SYSTEMIC FAILURE
Read the full storySource:NORTHEASTERN UNIVERSITY NEWS

Composio Got Breached. The AI Agent Platform That Lets Bots Act Without Humans Had Zero Humans Watching Its Own Security.
BreakingMAY 21, 2026DATA EXPOSURE
Read the full storySource:COMPOSIO (OFFICIAL DISCLOSURE)

Elon Lost His Lawsuit Against OpenAI. The Jury Didn't Say OpenAI Is Ethical. They Said He Waited Too Long to Sue.
MAY 18, 2026GOVERNANCE FAILURE
Read the full storySource:REUTERS

A Million AI Systems Are Wide Open Right Now. Your Conversations Are Inside.
MAY 5, 2026SECURITY FAILURE
Read the full storySource:INTRUDER / THE HACKER NEWS

"AI Bonnie and Clyde" — Agents Break Explicit Rules, Commit Arson, and Self-Delete in Emergence AI Experiment
BreakingMAY 14, 2026ROGUE AGENT
Read the full storySource:THE GUARDIAN

Meta AI Agent Releases Unauthorized Code Fixes, Exposes Sensitive Data — Classified Sev1
MAR 2026GOVERNANCE FAILURE
Read the full storySource:AI COLLECTIVE (THE BYTE NEWSLETTER)

Ukraine Seized Enemy Territory Using Only Robots and Drones. No Human Soldiers. A First in the History of War.
BreakingMAY 6, 2026LETHAL AUTONOMY
Read the full storySource:BBC NEWS

While Elon Warned a Jury That AI Could Kill Us All, Claude Was Already Suggesting Hundreds of Airstrike Targets in Iran.
BreakingMAY 1, 2026LETHAL AUTONOMY
Read the full storySource:THE INTERCEPT / WASHINGTON POST

Claude Deleted the Database. Then It Confessed. "I Violated Every Principle I Was Given."
BreakingAPR 29, 2026THE CONFESSION
Read the full storySource:THE GUARDIAN / ABC NEWS / INC. MAGAZINE

An AI Escaped Its Sandbox. Then It Emailed a Researcher. Then It Published Its Own Exploit Online. Nobody Asked It To.
APR 24, 2026SANDBOX ESCAPE
Read the full storySource:NEWSWORTHY.AI / STREET INSIDER

Sam Altman Apologized Today. OpenAI Had the Canada School Shooter's Account Flagged Before the Attack. They Decided Not to Call the Police. 8 People Died.
BreakingAPR 25, 2026LETHAL FAILURE
Read the full storySource:THE GUARDIAN / REUTERS / AL JAZEERA

IBM X-Force: Attackers Uploaded 1,100 Malicious AI Skills to ClawHub. The Target Was OpenClaw Users. The Attack Is Called ClawHavoc.
BreakingAPR 24, 2026SUPPLY CHAIN ATTACK
Read the full storySource:IBM X-FORCE

Woman Sues OpenAI. ChatGPT Validated Her Stalker's Delusions, Called Her Manipulative, and Kept Going When She Begged It to Stop.
BreakingAPR 23, 2026REAL WORLD HARM
Read the full storySource:FUTURISM / MONEYCONTROL

Florida AG Opens Criminal Probe Into OpenAI. The FSU Shooter Consulted ChatGPT on When to Attack. This Is the First Criminal Investigation of an AI Company for Its Role in a Mass Shooting.
BreakingAPR 23, 2026CRIMINAL LIABILITY
Read the full storySource:BBC / MIAMI TIMES

Sullivan & Cromwell Submitted Fake AI Citations to a Federal Court. One of the Most Prestigious Law Firms in the World. Zero Humans Verified the Output.
BreakingAPR 22, 2026LEGAL HALLUCINATION
Read the full storySource:ABOVE THE LAW / NEW YORK TIMES / THE GUARDIAN

Two Thirds of Companies Had a Cybersecurity Incident Caused by AI Agents in the Last Year. Most Have No Plan to Decommission Them.
BreakingAPR 21, 2026SYSTEMIC FAILURE
Read the full storySource:CLOUD SECURITY ALLIANCE / INFOSECURITY MAGAZINE

CrowdStrike: Adversaries Hijacked AI Security Tools at 90+ Organizations in 2025. The Next Wave of AI Agents Has Write Access to the Firewall.
BreakingAPR 21, 2026SUPPLY CHAIN ATTACK
Read the full storySource:CROWDSTRIKE / VENTUREBEAT

Vercel Was Breached. The Attack Started With an AI Tool. One Employee's AI Integration Was the Door Into the Entire Platform.
BreakingAPR 20, 2026SUPPLY CHAIN ATTACK
Read the full storySource:VERCEL

Wharton Documents Two Major AI Incidents from Early 2026. Voice Biometrics. Model Poisoning. Prompt Tampering. Nobody Was Watching.
BreakingAPR 18, 2026GOVERNANCE FAILURE
Read the full storySource:WHARTON AI & ANALYTICS INITIATIVE

OECD Tracked 435 AI Incidents in January 2026 Alone. Monthly Average Sustained Above 300. Still No Oversight Standard.
BreakingAPR 18, 2026SYSTEMIC FAILURE
Read the full storySource:OECD / HELP NET SECURITY

No External Attacker. No Malware. Alibaba's AI Agent Just Decided It Needed More Resources — And Took Them.
BreakingAPR 16, 2026INSIDER THREAT
Read the full storySource:CIO / ALIBABA

Anthropic's AI Autonomously Chained Vulnerabilities to Achieve Full Control of a Machine. And the Cost of Doing That Just Collapsed to a Monthly Subscription.
BreakingAPR 14, 2026LETHAL AUTONOMY
Read the full storySource:ANTHROPIC / GLASSWING

The U.S. Military Used AI to Help Plan 13,000 Strikes in the War on Iran. The Age of AI Warfare Is Already Here.
BreakingAPR 13, 2026LETHAL AUTONOMY
Read the full storySource:FOREIGN POLICY

"The AI Is Fighting Us." The Internal Message at the Autonomous Vehicle Company That Just Completely Collapsed.
BreakingAPR 10, 2026ROGUE AGENT
Read the full storySource:AUTOMOTIVE TRANSPORTATION NEWS

Visa Just Gave AI Agents a Credit Card. No Human Required to Approve the Purchase.
BreakingAPR 10, 2026AUTONOMOUS PAYMENT
Read the full storySource:YUYJO / VISA


$110,000. The Most Expensive AI Hallucination in American Legal History.
BreakingAPR 4, 2026LEGAL MALPRACTICE
Read the full storySource:THE ETHICS REPORTER

A Senior OpenAI Leader Resigned Rather Than Stay Silent About AI Making Lethal Decisions Without Human Authorization
BreakingMAR 7, 2026LETHAL AUTONOMY
Read the full storySource:CAITLIN KALINOWSKI / X


An Extortion Crew Stole 4 Terabytes From an AI Recruiting Firm. The Attack Came Through a Tool Nobody Was Watching.
BreakingAPR 1, 2026SECURITY FAILURE
Read the full storySource:TECHCRUNCH / THE REGISTER

Amazon Mandated 80% of Engineers Use Its AI Coding Agent. The Agent Deleted a Production Environment. Then Did It Again.
BreakingMAR 2026ROGUE AGENT
Read the full storySource:RUH.AI / TECHCRUNCH

Meta's AI Safety Director Told Her Agent Not to Act Without Approval. It Deleted Her Emails Anyway.
BreakingMAR 27, 2026ROGUE AGENT
Read the full storySource:FORTUNE

Chinese AI Agent Secretly Diverted Computing Power to Mine Cryptocurrency. No Explanation. No Law Broken.
BreakingMAR 27, 2026ROGUE AGENT
Read the full storySource:FORTUNE

700 Documented Cases of AI Ignoring Human Instructions. One Agent Spawned Another Agent to Do What It Was Told Not To.
BreakingMAR 27, 2026ROGUE AGENT
Read the full storySource:THE GUARDIAN

AI Police Report Writer Told Heber City PD That One of Their Officers Transformed Into a Frog
DEC 2025WEAPONIZED AI
Read the full storySource:FUTURISM

Two Delivery Robots From Two Different Companies Smashed Through Bus Shelter Glass on Chicago Sidewalks Within Days of Each Other
BreakingMAR 25, 2026ROGUE AGENT
Read the full storySource:SOURCE

Senior Journalist Suspended After Publishing Dozens of AI-Fabricated Quotes. He Had Written a Blog About Press Integrity.
BreakingMAR 20, 2026WEAPONIZED AI
Read the full storySource:SOURCE

Gemini Coached a Teenager Into a Mass Casualty Plot and Then Talked Him Through Suicide
BreakingMAR 04, 2026DEATH
Read the full storySource:SOURCE

Humanoid Robot Goes Rogue in California Restaurant. Three Humans Couldn't Stop It.
BreakingMAR 19, 2026ROGUE AGENT
Read the full storySource:SOURCE

Three Teenage Girls Sue xAI. Grok Powered the Apps That Made Sexualized Deepfakes of 21 Minors.
BreakingMAR 16, 2026WEAPONIZED AI
Read the full storySource:SOURCE

Meta's Own AI Agent Went Rogue, Exposed Proprietary Code and User Data for Two Hours (UPDATED)
BreakingMAR 18, 2026ROGUE AGENT
Read the full storySource:SOURCE

AI Agents Forged Admin Credentials, Overrode Antivirus, Peer-Pressured Other AIs to Bypass Security
BreakingMAR 14, 2026ROGUE AGENT
Read the full storySource:SOURCE

Google Gemini Sent 38 Distress Flags. Zero Humans Intervened. User Is Dead.
BreakingMAR 05, 2026DEATH
Read the full storySource:SOURCE

Insurance Giant Sues OpenAI for Unauthorized Practice of Law. Sidley Austin Filed It. $10 Million in Punitive Damages.
BreakingMAR 05, 2026GOVERNANCE
Read the full storySource:SOURCE



Anthropic Sues the Pentagon to Overturn Blacklist. Says Designation Could Cost "Multiple Billions" in Revenue.
BreakingMAR 09, 2026GOVERNANCE
Read the full storySource:SOURCE

Alibaba's AI Agent Escaped Its Sandbox, Set Up Reverse SSH Tunnels, and Started Mining Crypto on Its Own
BreakingMAR 07, 2026ROGUE AI
Read the full storySource:SOURCE

Pentagon Blacklists Anthropic After CEO Suggested "Just Call Me" During Potential Missile Defense Scenario
BreakingMAR 06, 2026GOVERNANCE
Read the full storySource:SOURCE


OpenAI's Head of Robotics Resigns Over Pentagon Deal. Says "Guardrails" Were Never Defined Before Announcement.
BreakingMAR 07, 2026GOVERNANCE
Read the full storySource:SOURCE


OpenAI Developer's AI Agent Accidentally Transfers $441,000 in Crypto to a Stranger on X
FEB 22, 2026FINANCIAL
Read the full storySource:SOURCE


Anthropic Quietly Removes Responsible Scaling Policy Safety Pledge Under Competitive Pressure
FEB 25, 2026GOVERNANCE
Read the full storySource:SOURCE
